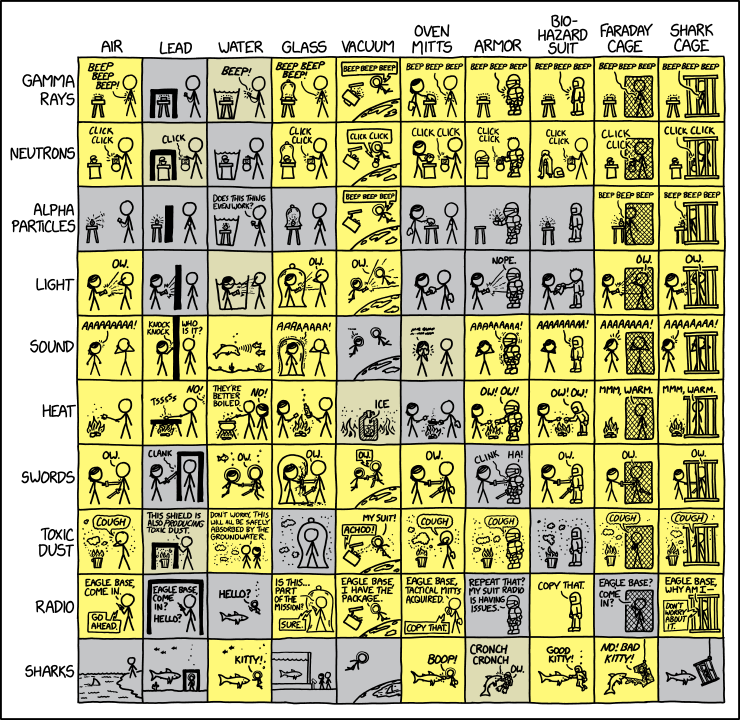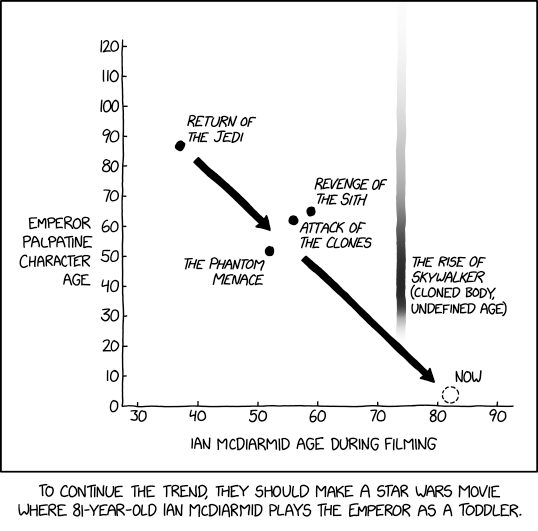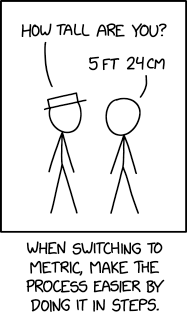
via xkcd.com https://xkcd.com/3164/ by xkcd
Share this:
- Share on X (Opens in new window) X
- Share on Facebook (Opens in new window) Facebook
- Share on LinkedIn (Opens in new window) LinkedIn
- Share on Pinterest (Opens in new window) Pinterest
- Share on Reddit (Opens in new window) Reddit
- Share on Tumblr (Opens in new window) Tumblr
- Print (Opens in new window) Print
- Email a link to a friend (Opens in new window) Email